Enfoques comunes de la inteligencia artificial (IA) en el mercado financiero: ¿qué funciona realmente? 4 ejemplos
En este post se pretenden explicar los acercamientos más típicos al mundo del trading usando inteligencia artificial, pondré algunos ejemplos y explicaré qué funciona y qué no funciona.
Para empezar, podemos ver internet plagados de post sobre inteligencia artificial aplicada al trading en donde se obtienen unos beneficios abrumadores, “el santo grial”. Algunos ejemplos de artículos del estilo son:
- https://www.cleveritgroup.com/blog/prediccion-del-precio-del-bitcoin-usando-lstm-con-keras-y-tensorflow-parte-1
- https://dspace.uib.es/xmlui/bitstream/handle/11201/158443/tfm_2020-21_MADM_lnm464_4096.pdf?sequence=1
- https://www.garcia-ferreira.es/lstm-simple-para-el-pronostico-de-la-bolsa/
- https://www.cleveritgroup.com/blog/prediccion-del-precio-del-bitcoin-usando-lstm-con-keras-y-tensorflow-parte-1
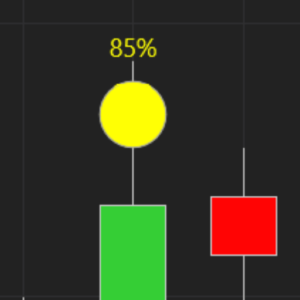
Todos esos artículos y tésis están muy bien, el único problema es: que no funciona. Si entráis a alguno de los artículos (os he puesto 4 pero hay miles en internet) veréis que todos tienen una cosa en común, y es que la IA parece predecir el precio muy bien, muy de cerca, casi perfecto. Y digo casi, porque en realidad no es ni siquiera una predicción, lo único que hacen es un shift (desplazamiento) del precio por 1 unidad, dependiendo del artículo puede ser clavado o estar suavizada (una especie de EMA).
Ejemplo:
 en el mercado financiero: ¿qué funciona realmente? 4 ejemplos 1")
Los problemas que presenta la Inteligencia artificial aplicada al trading:
La mayoría de los artículos construyen modelos basados en LSTM (Long Short-Term Memory), una forma popular de redes neuronales recurrentes, que son excelentes para detectar y memorizar patrones a largo plazo en series temporales (como es el trading). Sin embargo, hay varios problemas inherentes a la aplicación directa de LSTM en el trading:
- Overfitting: Dada la alta dimensión y complejidad de los datos de mercado, es fácil para un modelo ajustarse demasiado a los datos de entrenamiento. Esto significa que el modelo aprenderá “de memoria” los patrones específicos de este conjunto de datos, pero fallará al enfrentarse a nuevos datos o condiciones de mercado.
- Aunque pensemos que no, ven el futuro: Muchos modelos cometen el error de “tener datos del futuro”, es decir, durante el training o test, se utiliza información que no estaría disponible en una situación real de trading. A esto muchos de los que han hecho un cursillo de IA pero no tienen ni idea dirán: “No, pero si yo he separado mis datos en mi training y test, el modelo no ve los datos de test etc etc”, tonterías, no tienen ni idea de como funciona la IA entonces. El trading es diferente y en otro post explicaré los errores más comunes y cómo evitarlos.
- Los datos no están correlacionados entre sí, en el sentido de que no son estacionarios: Esto significa que sus propiedades estadísticas cambian con el tiempo. Las LSTM, por mucho que puedan detectar patrones, no pueden anticipar cambios fundamentales o eventos externos que cambien estas propiedades.
Entonces, ¿cómo deberíamos abordar el trading con IA?
- RL: En lugar de simplemente predecir precios, una estrategia más robusta es utilizar algoritmos de refuerzo del aprendizaje que aprenden a tomar decisiones de trading basadas en la maximización de recompensas (como los beneficios).
- Modelos híbridos: Combinar técnicas de machine learning, como las LSTM, con modelos clásicos de trading (FF.NN.) y análisis técnico puede funcionar, tras un largo camino de desarrollo y ajustes al modelo.
- RL sobre estrategias de trading “tradicionales”: Estos modelos pueden usar la IA para refinar y optimizar señales de dichas estrategias, ejemplos se darán en otro post.
- Inclusión de datos alternativos: Además de los datos de precios, se pueden incluir fuentes de datos alternativas como noticias, datos de redes sociales o indicadores macroeconómicos. En donde la IA puede ser útil para procesar y extraer señales de estos vastos conjuntos de datos.
- Multi-modelo (me gusta más llamarlo ensambling): Utilizar múltiples modelos y combinar sus predicciones puede ayudar a reducir el riesgo y mejorar la robustez de las estrategias. Personalmente a mi esto me gusta mucho, básicamente es usar diferentes activos para entrenar un modelo al mismo tiempo (un modelo local por cada time series conectada a un modelo global).
Casi la totalidad de los modelos para “predecir el precio” se basan en LSTM, lo cual es por si mismo, inútil. Ahora se esperaría que introduciese otras técnicas como clustering, RF y tal, pero lo cierto es, que no funcionan para lo que trata el artículo. Otras técnicas pueden usarse para analisis de datos o modelos alternativos que alimentan al modelo principal, pero poco más. Ahórrate meses con esta serie de artículos…
Leave a Reply
Want to join the discussion?Feel free to contribute!